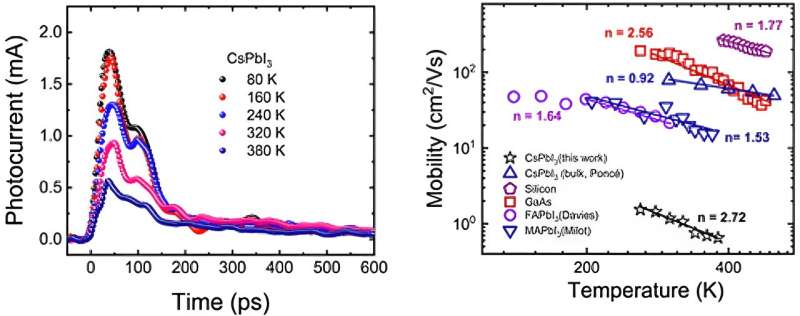
对生成式人工智能技术的担忧似乎几乎与技术本身的传播速度一样快。这些担忧源于对虚假信息可能以前所未有的规模传播的不安,以及对失业、对创造性工作失去控制的担忧,更长远地说,人工智能变得如此强大,以至于它会导致人类灭绝。
这些担忧引发了对人工智能技术进行监管的呼吁。欧盟(eu)等一些国家的政府对本国公民要求监管的呼声做出了回应,而英国和印度等一些国家的政府则采取了更为自由放任的做法。
在美国,白宫于2023年10月30日发布了题为《安全、可靠、值得信赖的人工智能》的行政命令。它制定了指导方针,以减少人工智能技术带来的近期和长期风险。例如,它要求人工智能供应商与联邦政府分享安全测试结果,并呼吁国会制定消费者隐私立法,以应对人工智能技术吸收尽可能多的数据。
鉴于监管人工智能的动力,重要的是要考虑哪些监管方法是可行的。这个问题有两个方面:今天什么在技术上可行,什么在经济上可行。查看人工智能模型的训练数据和模型的输出也很重要。
监管人工智能的一种方法是将训练数据限制在人工智能公司已获得许可使用的公共领域材料和受版权保护的材料。人工智能公司可以精确地决定用于训练的数据样本,并且只能使用允许的材料。这是技术上可行的。
这在经济上是部分可行的。人工智能生成的内容的质量取决于训练数据的数量和丰富程度。因此,对于AI供应商来说,不必将自己限制在获得许可使用的内容上,这在经济上是有利的。然而,如今一些从事生成式人工智能的公司宣称,他们只使用获得许可的内容,这是一项可销售的功能。Adobe的Firefly图像生成器就是一个例子。
2. 将输出属性设置为训练数据创建者
将AI技术的输出归给特定的创作者(艺术家、歌手、作家等)或创作者群体,这样他们就可以得到补偿,这是调节生成AI的另一种潜在手段。然而,所使用的人工智能算法的复杂性使得无法确定输出是基于哪个输入样本。即使这是可能的,也不可能确定每个输入样本对输出的贡献程度。
归属是一个很重要的问题,因为它可能决定创作者或其作品的许可持有人是会接受还是反对人工智能技术。好莱坞编剧为期148天的罢工,以及他们为保护自己不受人工智能侵害而赢得的让步,展示了这个问题。
在我看来,这种处于人工智能输出端的监管在技术上是不可行的。
对人工智能技术的一个直接担忧是,它们将引发自动生成的虚假信息活动。这种情况在不同程度上已经发生过——例如,乌克兰-俄罗斯战争期间的虚假信息运动。这是民主的一个重要问题,因为民主依赖于通过可靠的新闻来源获得信息的公众。
在创业领域,有很多活动旨在开发能够区分人工智能生成内容和人类生成内容的技术,但到目前为止,这项技术还落后于生成式人工智能技术。目前的方法侧重于识别生成人工智能的模式,从定义上讲,这几乎是一场必败之战。
这种调节人工智能的方法也在输出端,目前在技术上是不可行的,尽管这方面可能会取得快速进展。
我们可以将AI生成的内容归因于特定AI供应商的技术。这可以通过易于理解和成熟的加密签名技术来实现。人工智能供应商可以对其系统的所有输出进行加密签名,任何人都可以验证这些签名。
这项技术已经嵌入到基本的计算基础设施中——例如,当网络浏览器验证你正在连接的网站时。因此,人工智能公司可以轻松部署它。这是一个不同的问题,是否需要依赖人工智能生成的内容,这些内容来自少数几个可以验证签名的大型、成熟的供应商。
所以这种形式的监管在技术上和经济上都是可行的。该规定针对的是人工智能工具的输出端。
对于政策制定者来说,了解每种监管形式的可能成本和收益是很重要的。但首先,他们需要了解哪些在技术上和经济上是可行的。
公司提供
nversation
本文转载自The Co在知识共享许可下的对话。阅读原文。
引用控制人工智能意味着要找出哪些监管方案在技术上和生态上都是可行的
名义上(2024年,1月18日)检索自2024年1月18日https://techxplore.com/news/2024-01-reining-ai-figuring-options-feasible.html本文档
作品受版权保护。除为私人学习或研究目的而进行的任何公平交易外,未经书面许可,不得转载任何部分。的有限公司
内容仅供参考之用。